Visual recognition from images and videos
Automatic recognition of visual entities under different learning scenarios.
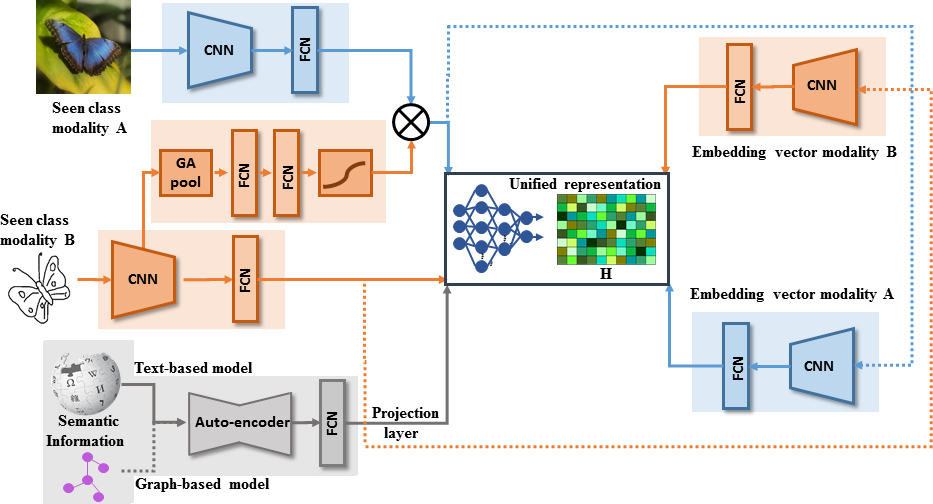
Our research in visual recognition from images and videos focuses on enabling machines to understand and interpret complex visual scenes under unconstrained conditions. We address key challenges such as the semantic variability of visual categories, temporal dynamics in video data, and the need for context-aware recognition. In video-based reasoning, we emphasize the extraction of temporally coherent representations and scene graphs that can capture object interactions and event semantics. For image-based recognition, we investigate methods to align visual content with semantic concepts in a scalable manner. Our work also explores strategies for handling label noise, sparse supervision, and structured prediction across diverse visual tasks. These efforts are aimed at building perceptual models that can function reliably across varying spatial, temporal, and conceptual granularities in both static and dynamic settings.